Overview and Architecture of Apache Spark #
Introduction #
Apache Spark is an open-source unified analytics engine designed for large-scale data processing. Spark provides high-level APIs in Java, Scala, Python, and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools, including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming for stream processing.
Key Features #
- Speed: Spark extends the MapReduce model to efficiently support more types of computations, including interactive queries and stream processing. It achieves up to 100 times faster performance for certain applications by exploiting in-memory computing and other optimizations.
- Ease of Use: Spark offers APIs in Scala, Java, Python, and R, making it accessible to a wide range of developers. The higher-level libraries for SQL, streaming, and machine learning are seamlessly integrated.
- Unified Engine: Spark is a unified engine for processing big data. It can process both batch and real-time data using a unified architecture and API.
- Advanced Analytics: Spark combines SQL, streaming, and complex analytics in one platform, making it easier to build end-to-end data workflows.
Core Components #
- Spark Core: This is the foundation of the Spark platform, providing basic functionality like task scheduling, memory management, fault recovery, interacting with storage systems, and more.
- Spark SQL: This module provides a programming interface for working with structured data using SQL and DataFrames. It also includes a cost-based optimizer, columnar storage, and code generation for efficient query execution.
- Spark Streaming: This component enables scalable and fault-tolerant stream processing of live data streams. Data can be ingested from various sources and processed using complex algorithms expressed with high-level functions.
- MLlib: Spark’s machine learning library that provides scalable machine learning algorithms. It supports a wide range of statistical and machine learning algorithms.
- GraphX: A graph computation engine built on top of Spark that allows for the manipulation of graphs and performing graph-parallel computations.

Architecture #
Spark architecture is designed to be both extensible and efficient, composed of several layers that handle different aspects of data processing.
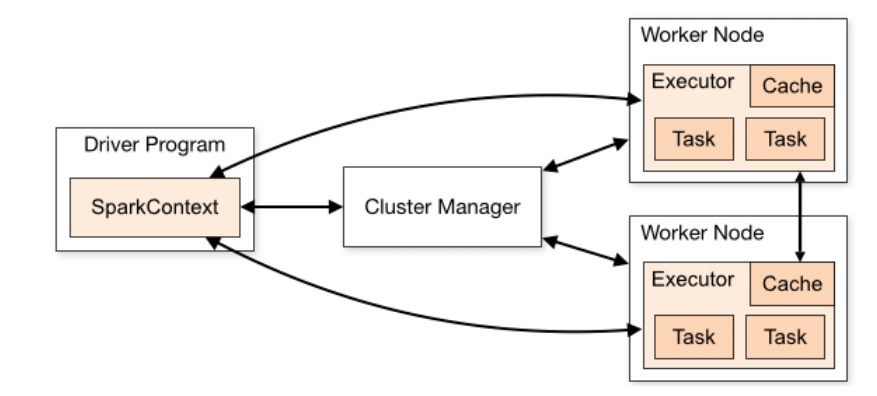
- Driver Program: The entry point of a Spark application. It contains the SparkContext, which coordinates the application by managing the distributed processes.
- Cluster Manager: Spark can be deployed on various cluster managers:
- Standalone Cluster Manager: A simple built-in cluster manager that comes with Spark.
- Apache Mesos: A general cluster manager that can run Hadoop MapReduce and other applications.
- Hadoop YARN: The resource manager in Hadoop 2.
- Kubernetes: For containerized deployment.
- Workers/Executors: These are the distributed agents that run on the worker nodes in the cluster. Each executor runs tasks, processes data, and reports the results back to the driver.
- RDD (Resilient Distributed Dataset): The fundamental data structure of Spark, representing an immutable distributed collection of objects that can be processed in parallel. RDDs support two types of operations:
- Transformations: Operations on RDDs that return a new RDD, like
map,filter,reduceByKey. - Actions: Operations that trigger execution and return a result to the driver program or write data to an external storage system, like
collect,count,saveAsTextFile.
- Transformations: Operations on RDDs that return a new RDD, like
Execution Flow #
- Job Submission: A Spark job is submitted through the driver program, which creates the SparkContext.
- Task Scheduling: The driver program converts the user code into a DAG (Directed Acyclic Graph) of stages. Each stage contains a set of tasks based on the partitioning of the data.
- Task Execution: The cluster manager allocates resources for the tasks, and the executors execute the tasks. Executors run the tasks and store the computation results in memory or disk.
- Result Collection: The results are collected back to the driver program or written to the storage system.
Data Abstraction #
- RDD: Provides low-level API and is fault-tolerant and immutable. Suitable for transformation and action operations.
- DataFrames: Higher-level API for working with structured data, inspired by data frames in R and Python. They provide optimizations through the Catalyst optimizer.
- Datasets: Type-safe version of DataFrames with the benefits of RDDs. They are available in Scala and Java.
Conclusion #
Apache Spark is a versatile and powerful tool for big data processing. Its architecture is designed for speed and ease of use, making it suitable for a wide range of data processing tasks, from batch processing and real-time analytics to machine learning and graph processing. Spark’s ability to handle different types of workloads with a unified engine simplifies the development and deployment of complex data workflows.



